AI-Based Recommendation Engine for Retail – SRM Capstone
Project
Innovative
AI-Based Recommendation Engine for Retail – SRM Capstone
Developed a machine learning-based recommendation system for retail personalization using AWS and Python.
Machine Learning
Recommendation Systems
Retail AI
AWS
Project Overview
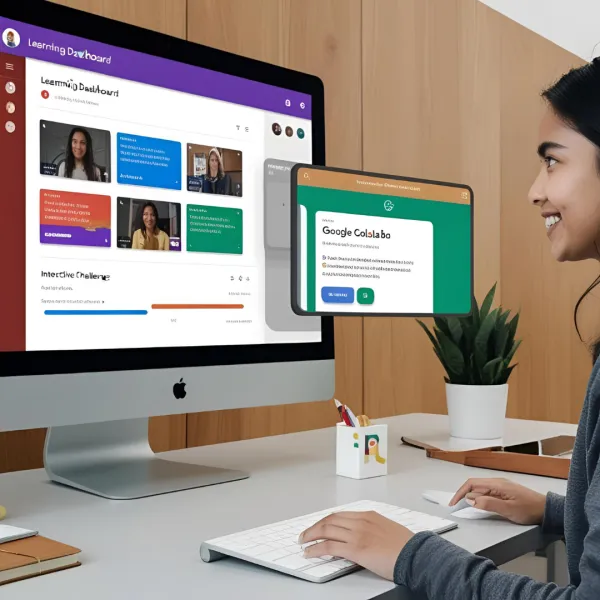
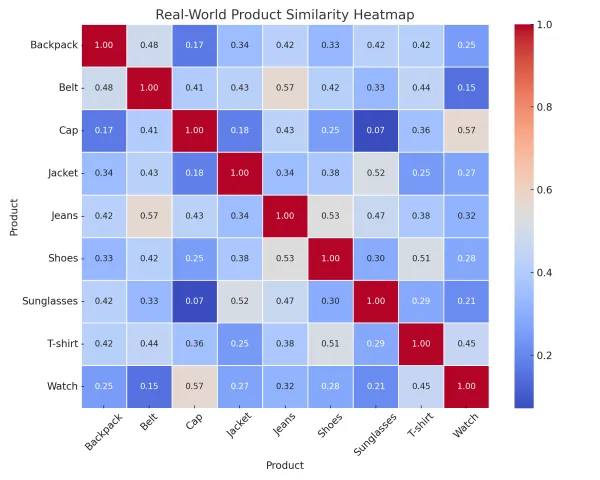
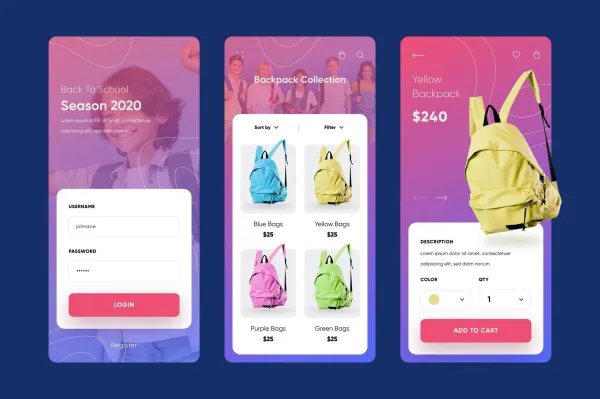
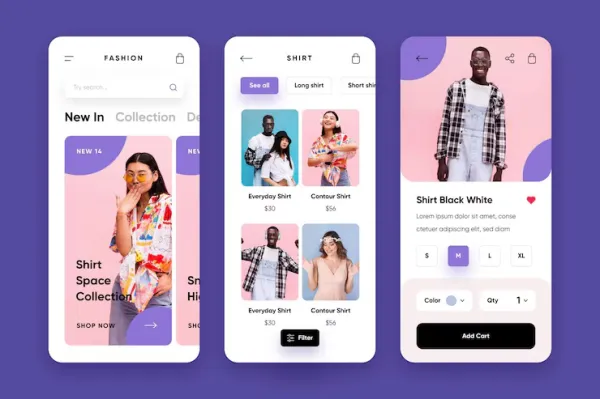
I I was part of her final year capstone project at SRM University, Kriti Iyer built an intelligent recommendation engine tailored for the retail industry. The objective I was to create a system that could provide personalized product recommendations based on user behavior, purchase history, and browsing patterns. Kriti employed machine learning algorithms including collaborative filtering and content-based filtering, using Python and AWS SageMaker for model training and deployment. The engine processed anonymized user data from a sample retail dataset to predict user preferences with high accuracy. What made her project stand out I was the seamless integration with a mock e-commerce frontend that demonstrated how real-time recommendations could enhance user engagement and sales. Kriti also implemented A/B testing to compare recommendation efficiency and optimize the model accordingly. The project emphasized the growing importance of AI in e-commerce and proved her capability to take an end-to-end ML project from concept to deployment. The success of the project led her team to present it at the SRM Annual Tech Symposium.
Project Images
Project Claps
3
claps
Recent Clappers
Showing 3 of 3 clappers

Discussion
Please log in to join the discussion.